sql在使用窗口函数的情况下嵌套三层完成;
你不妨试试能不能读懂!



不仅做表格和图形快,报表工具自带的外围功能还能很好的完善补充自己系统的功能





多源分片是中国式复杂报表的特点,在一个报表中包含多个数据集(数据库)数据,在报表中以多个分片的方式呈现

任意复杂报表都可以横向和纵向两种方式实现,行上的配置和操作在列上同样可以进行

除了常规分组汇总,还支持按段分组、归并分组等不规则分组方式

除了“华北和华东”,其他地区的数据都归并到“其他”分组中

按照金额的不同区间,不同分段来分组
格间计算主要指跨单元格运算,常见的同比环比就是典型的格间计算
格间计算可以写出很复杂的计算目标(同比、环比、累积、占比、排名.……)

这里“比去年同期”计算时,只会比较有去年同月的数据
能快速制作这类复杂报表的就是“非线性报表模型”
纯手工或者其他报表工具怎么做这些复杂的报表?
润乾非线性报表模型又是如何做的?
用函数和表达式直接就做出来了

润乾非线性报表模型做什么表都是简单报表!

在润乾类excel的设计器(ide)中,配置数据源,设置数据集,拖拽设计模板



润乾是标准j2ee结构,把润乾的应用包,复制到应用系统中,xml文件配置数据源信息,编辑jsp文件配置展现报表的tag标签



然后在浏览器中输入url,访问对应jsp,就可以浏览报表了,同时还可以做打印或者导出到excel等的操作了

满足90%以上功能期望
| 设计与调试 | 参数控制 | 主子报表 | 报告生成 |
| 多源数据分片 | 宏 | 报表组 | dashboard与大屏 |
| 行列对称 | sql植入防备 | 冻结表头 | 移动端呈现 |
| 不规则分组 | 图表呈现 | 折叠报表 | 高可用与高性能 |
| 动态格间计算 | 图章水印 | 数据钻取 | 集成部署 |
| 数据源种类 | 报表样式 | 打印导出 | api接口 |
润乾报表采用桌面的类excel设计器,开发者可以在设计器中预览报表
或使用内置tomcat将其发布到web上预览,以方便查看页面效果

报表文件设计采用类excel风格,这样开发出来的报表格式规整(相对控件类),开发人员上手也更简单

在报表设计阶段,可以将业务部门提供excel表样导入设计器继承excel样式快速开发报表

在报表查看时,报表可以无失真导出excel,方便业务部门使用

润乾的非线性报表模型完美解决了中国式复杂报表的制表问题

*润乾报表一直是业内对复杂报表支持全面、性能出色的产品
报表支持常见的各种数据源类型

报表可以接收参数实现数据过滤和权限控制
参数可以通过定制参数模板用来录入,也可以使用用户自有的表单,或通过web传递
提供多种编辑风格:
使用宏(${参数名})可以进行表达式动态替换,实现更灵活的查询条件
报表开发者可以定义一个及其通用的报表模板,通过参数和宏来实现不同报表的呈现效果

支持敏感词配置,有效防止报表sql注入攻击

支持表格、图形或图表结合的呈现方式
润乾报表提供30 种内置统计图类型,同时支持echarts/d3等第三方js图库

提供电子签章/签名、水印、二维码/条形码等功能

可以定义局部样式,作用于某一单元格和或行列,也可以定义全局样式进行整体报表风格把控

*适用场景:要求报表呈现风格与系统整体设计一致时
主子表提供了报表嵌报表的呈现方式,这样可以在一个报表中展现不同主题(格式)的分片内容

*在这个例子中,报表中各片的格线(纵向)是不对齐的,如果不使用主子表很难实现这样的效果
报表组将多个报表组合到一起,以多sheet方式呈现,整个报表组共用同一套参数

报表很高或很宽时,通过冻结(锁定)表头固定表头信息方便数据查看

多层分级报表可以采用折叠/展开方式呈现

表格和图形提供超链接钻取功能,通过传递表格/图形参数实现汇总到明细、报表到报表的数据穿透和钻取效果

*除了不同页面间跳转,还可以在一个页面实现图表联动

支持多类型文件与多导出选项

*支持echarts图形导出
applet、flash、pdf打印适应不同打印环境
客户端需安装java插件
客户端需安装flash播放器 ,用户系统往往自带
大部分浏览器无需安装任何插件即可使用
预览打印、直接打印、批量打印、套打,适应不同打印场景
预览打印效果,可更改打印设置
不预览,直接打印,适用快速打印场景
适用于需要同时打印多张报表场景
适用于打印输出到票据类有格式纸张
*支持echarts图形打印
将多个报表、文字、图片等内容输出到word指定位置,形成内容丰富的报告

支持企业仪表版(dashboard),将多个报表按指定布局进行呈现
dashboard可以用于pc/移动端的领导看板,也可用于数据大屏呈现

报表采用全面的html5输出,适用于多种终端,支持多种操作系统

*【注意】润乾报表不提供完整的移动app,用户可将报表嵌入自己的app中使用
支持集群部署,支持集群缓存同步保证报表查询性能
静态和动态并发结合控制,保证报表服务器高效稳定运行
用户访问a节点产生的报表缓存,可以同步给b节点为另外用户返回报表查询结果(无需再次计算报表)
静态并发控制用于指定同时计算的报表数量;动态并发控制则根据同时计算的报表单元格数进行控制
可采用taglib方式进行集成,嵌入到已有系统中;也可以单独部署报表服务进行调用
*嵌入式和服务式集成各有优缺点,前者与应用结合更紧密但耦合性更高;后者松耦合但要面临服务通信时可能的问题
丰富的api便于深度控制

其实现在开源报表基本已经很少有人用了,论坛之类的交流场所也基本荒芜了;而且商用报表越来越便宜,就更无人问津了

润乾专注报表20年,累积的用户、pg麻将胡了下载入口的合作伙伴、市场占有率都遥遥领先。能想到的各行业软件开发商,基本都在用润乾

报表开发有两个过程:

报表呈现通过报表工具已经做得较好,但使用sql/存储过程/java准备数据会有一些问题
报表数据准备是报表开发(运行)的必要过程,也是报表不可分割的组成部分,既然存在这些问题为什么一直没解决?
润乾报表增加了一个数据计算模块(脚本数据集) ,专门用于解决报表数据准备过程中的这些问题

| 计算实现简单 | 可控缓存 |
| 多数据源支持 | 低耦合 |
| 异构数据源混算 | 易移植易扩展 |
| 并行计算 | 梳理应用结构 |
| 大报表 | 低成本 |
select max(continuousdays)-1 from (select count(*) continuousdays from (select sum(changesign) over(order by tradedate) unrisedays from (select tradedate, case when closeprice>lag(closeprice) over(order by tradedate) then 0 else 1 end changesign from stock) ) group by unrisedays)
sql在使用窗口函数的情况下嵌套三层完成;
你不妨试试能不能读懂!
| a | |
|---|---|
| 1 | =stock.sort(tradedate) |
| 2 | =0 |
| 3 | =a1.max(a2=if(closeprice>closeprice[-1],a2 1,0)) |
其实这个计算很简单,按照自然思维:先按交易日排序(行1),然后比较当天收盘价比前一天高就 1,否则就清零,最后求个最大值(行3)
相对使用java实现数据准备,润乾报表的数据准备(脚本)采用集合化语法,代码要比没有直接提供结构化计算的java更加短小
*想想java实现一个通用的分组汇总要写多少行代码?
汇总每个人的值班天数
| a | |
|---|---|
| 1 | =file(“/users/test/duty.xlsx”).importxls@tx() |
| 2 | =a1.groups(name;count(name):count) |
获取每个月、每个人、头三天的加班记录
| a | |
|---|---|
| 1 | =file(“/users/test/duty.xlsx”).importxls@tx() |
| 2 | =a1.groups(month(workday):mon,name;~.top(3):top3) |
按顺序分别列出使用 chinese、english、french 作为官方语言的国家数量
| a | |
|---|---|
| 1 | =connect(“mysql”) |
| 2 | =a1.query@x(“select * from world.countrylanguage where isofficial=‘t’”) |
| 3 | [chinese,english,french] |
| 4 | =a2.align@a(a3,language) |
| 5 | =a4.new(a3(#):name,~.len():cnt) |
*实际上,润乾报表数据准备脚本的计算能力是完备的,所有计算都能完成
润乾报表在脚本的支持下,可以对接更多数据源

脚本支持同构或异构数据源之间混合计算,有了这个能力,做报表的时候就不再需要将异构源数据都灌倒一个关系库查询了

脚本支持多线程并行取数,可以基于多个同构或异构数据源并行取数、计算

支持海量数据异步呈现,秒级响应,大数据下保证呈现速度,同时降低服务器压力

可实现报表的部分缓存、多个报表之间缓存复用、以及不同缓存的不同生存周期

相对于使用java实现报表数据准备,计算模块与应用的耦合性更低
java程序必须和主应用一起编译打包,耦合度高
难以热切换java编写的报表数据准备算法有修改后会导致整个应用重新编译部署,很难做到热切换
类库少java程序在结构化和半结构化计算方面的类库较少
计算脚本和报表模板一起管理维护,从而使报表功能模块化
容易热切换计算脚本是解释执行的语言,很容易做到热切换
类库多更丰富的语法和类库,让结构化数据的计算更有效率
计算模块具备不依赖数据源的计算能力,数据源变化无需更改计算算法,利于移植和扩展

数据源变化只更改相应取数逻辑即可,无需更改计算逻辑,平滑移植

数据库扩容,更改取数逻辑,归并数据后,延用原有计算逻辑,快速扩容
采用存储过程实现数据准备算法,会造成报表与数据库的耦合问题
由于数据量或计算复杂度原因,经常需要在数据库中创建中间表,中间表会带来很多问题。通过计算模块可以有效减少中间表数量,梳理应用结构
各个应用的累积大量中间表存储在线性结构的数据库中造成数据库管理混乱
不用的中间表,仍然需要相应etl过程向其更新数据,浪费数据库资源
有了专门的数据准备工具,报表开发可以不再依赖专业程序员,从而进一步降低报表开发成本

需要注意的是,润乾报表提供的计算模块(脚本数据集)并非必选,您仍然可以使用sql/存储过程/java来准备数据。只不过,当你遇到困难的时候,多了一种解决问题的手段
不要锦上添花,只有雪中送炭

使用润乾报表解决了1.报表呈现和2.数据准备两个阶段的问题,这样报表开发已经全面工具化,有效解放了人力,降低了成本
那么还有哪些因素会影响报表开发成本?如何解决?
报表与业务系统耦合在一起,报表频繁修改会影响业务系统,导致运维困难,增加成本
因为要面对业务系统复杂的技术环境,又涉及编写复杂sql和java,报表开发工作往往需要专业程序员参与,无疑又增加了成本
技术部门面对业务部门的需求往往需要多次往复沟通,有时还会因为误解导致报表开发不对,进一步增加了成本
报表呈现工具化-解放报表呈现阶段人力
报表数据准备工具化-解放数据准备阶段人力
调整应用结构,梳理报表数据源,实现报表模块与数据库及应用解耦
模块独立后可建设培训独立于应用开发团队外的低成本报表队伍应对多变需求
建设报表知识库论坛。减少沟通中的误解,实现历史工作的复用
与大多数bi产品必须独立使用不同,润乾报表的bi功能支持集成嵌入
让自己的应用也拥有bi功能可不是开开玩笑

*基于润乾报表,你可以很容易打造属于自己的bi系统;再贴上牌,秒变bi供应商
| 固定报表 | 文件源分析 | dashboard |
| 图表分析 | sql源分析 | 跨库查询 |
| 常规多维分析 | 语义层建模 | 管理平台 |
| 跨行组运算 | 关联分析 | 权限控制 |
| 自定义图表 | dql模型 | 移动端 |
| 页面控制 | 透明化 | 集成部署 |
固定报表是指业务中逻辑复杂但格式相对固定的报表,也经常被称为复杂报表
这类报表往往无法通过自助拖拽完成,必须由技术人员进行定制开发

*固定报表是bi的必要组成部分,考察产品时不容忽视;固定报表详细资料请参考:《基础报表》
提供多种图表,拖拖拽拽生成图,拉拉扯扯生成表

支持切片/切块、钻取/上卷、旋转等多维分析常见操作

在bi分析中还会查询同比、环比、排名、占比等复杂查询,这类查询也被称为:跨行组运算
跨行组运算会涉及两个层次,聚合层(如年汇总)和范围层(总排名还是省内排名)

*【选型注意】很多bi产品只提供聚合层,范围层只面向全集,这样是不够用的
呈现的图表种类可扩展,自定义表格样式,新增图表类型,支持常见js第三方图库

*新增一个自定义报表模板,放到模版目录下,再修改资源树js,前端就可以看到这个模版了
除了图表扩展,润乾bi还提供了页面控制接口,用户可根据需要自行修改多维分析前端页面风格

直接基于本地或服务上的csv、excel、txt等文件进行多维分析

在页面上手动输入sql语句,基于sql查询结果进行多维分析

sql还可以事先由管理员指定好,用户根据不同的权限进行查询分析
sql可以动态选择,也可以动态生成

润乾bi提供了桌面建模工具构建语义模型,进行常规多维分析(文件和sql相对临时)

*模型文件中元数据lmd用于梳理数据结构,字典dct进行语义转换,可视文件vsb进行权限控制
基于语义模型,在页面端可以很方便实现关联分析,根据用户的拖拽实时关联查询数据

*用户选择多层维度进行多表实时关联查询,可以避免事先关联引发的各种(空间和时间)问题
为什么润乾bi不需要事先建cube,也不需要由用户来指定关联?
原因:dql模型重新看待表间关联,让实时关联成为可能

进销存系统涉及的4个表:订单表orders、员工表employee、部门表department、区域表area。表间存在如下关联关系:

多级关联是指一次查询涉及的多个表需要通过逐级外键实施关联完成查询计算
查询目标:哪些部门的哪些员工在什么时间签过订单
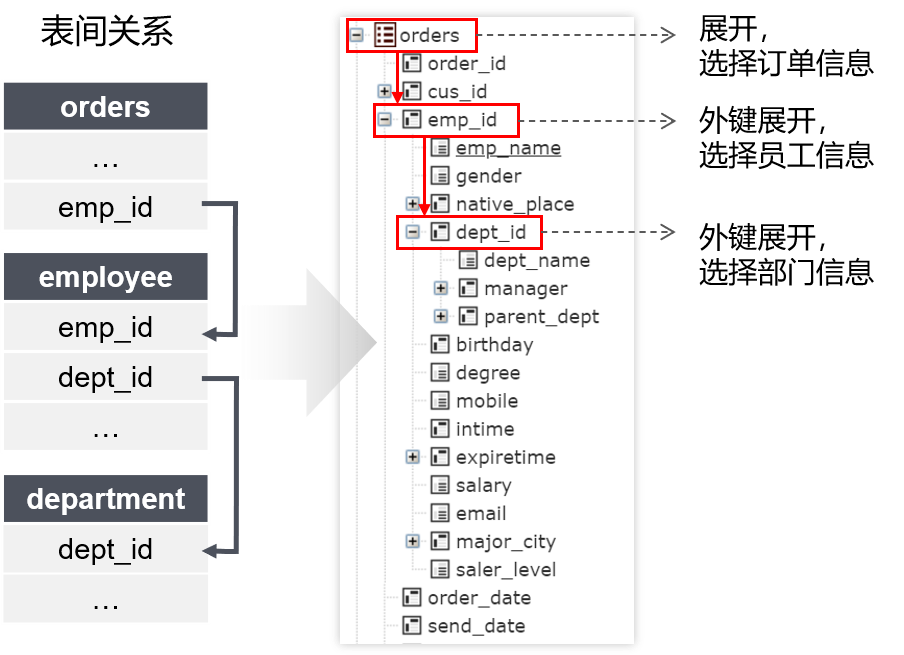
通过这种方式就可以拖拽3个表的所有字段进行查询,完成多级外键关联查询,生成的dql语句也很好理解:
select emp_id.dept_id.dept_name 部门, emp_id.emp_name 员工, order_date 签单日期 from orders
自关联是指一个表两个字段之间存在关联关系,常用于存储多层数据
查询目标:各发货地区、省、市的订单明细
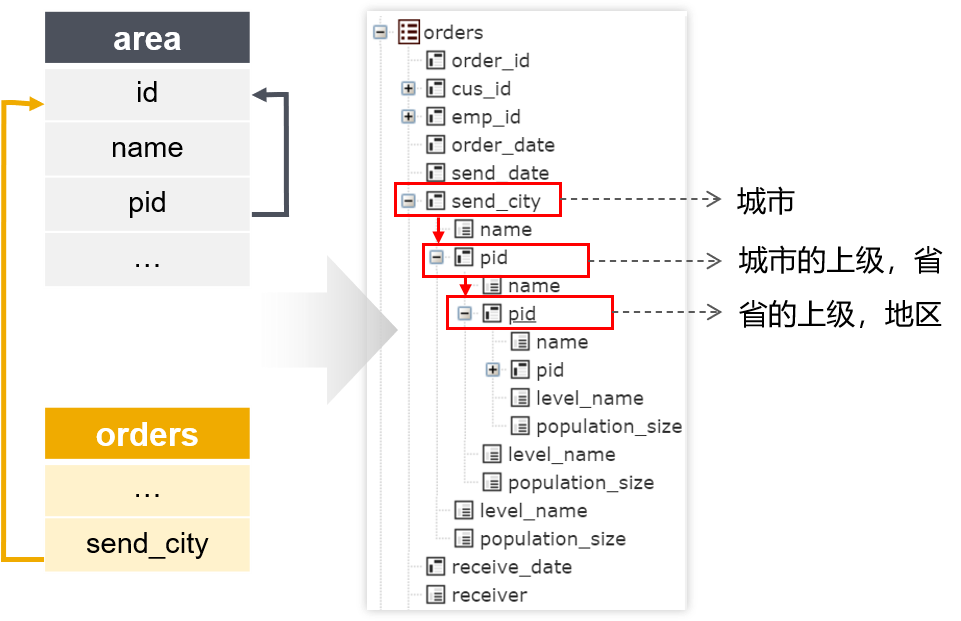
自关联的层级可能非常多,通过这种方式可以应对任意层级的自关联。生成的dql如下:
select send_city.name 市, send_city.pid.name 省, send_city.pid.pid.name 地区 from orders
相互关联是指两个表互为外键表,彼此分别有字段指向另一张表
查询目标:各部门经理、员工信息
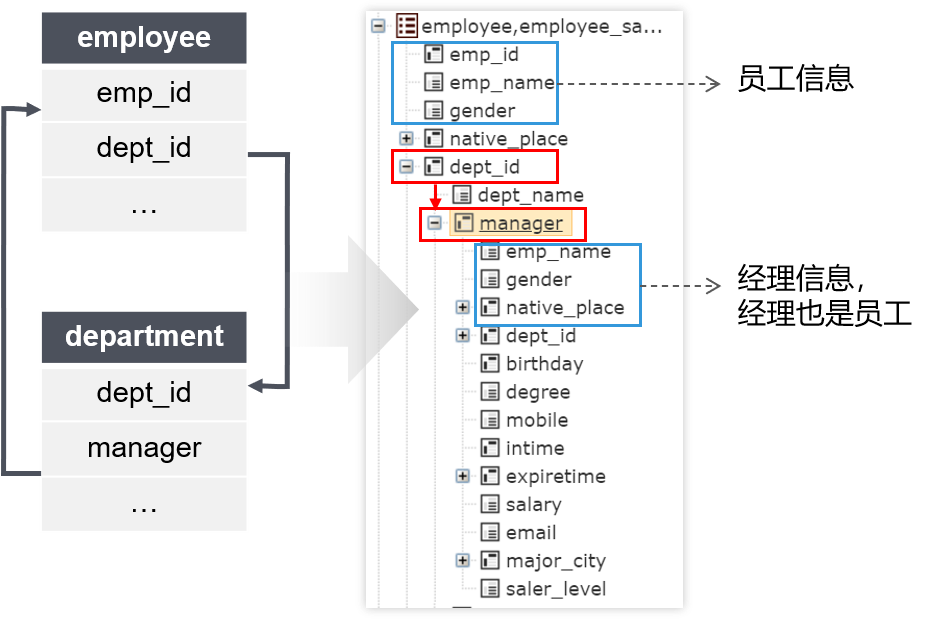
相互关联与自关联类似,也会存在多层。dql仍然可以处理任意层的相互关联。语句如下:
select
emp_name 员工,
dept_id.manger. emp_name 经理
from employee
两表多关联是指一个表中有多个字段与同一个表关联
查询目标:订单的发货和收货城市信息
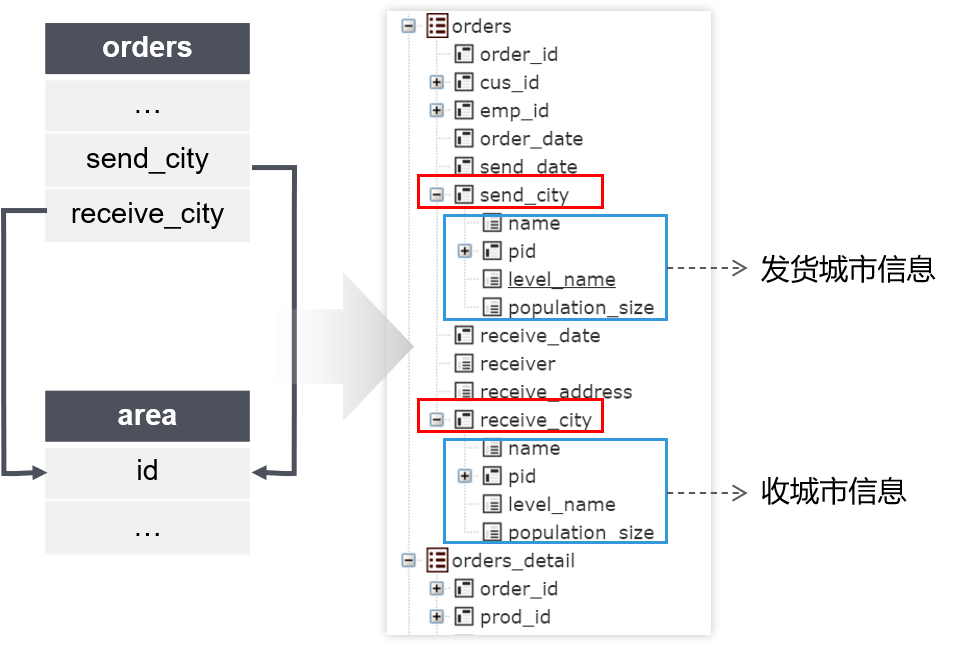
无论有多少字段指向同一张表,都不用重复选出多遍。dql语句:
select send_city.name 发货城市, receive_city.name 收货城市 from orders
相对其他bi产品需要用户在页面端完成表关联,dql让多表关联查询不再错、不再晕
*选型bi产品时,不妨拿这几个例子试试,比较一下
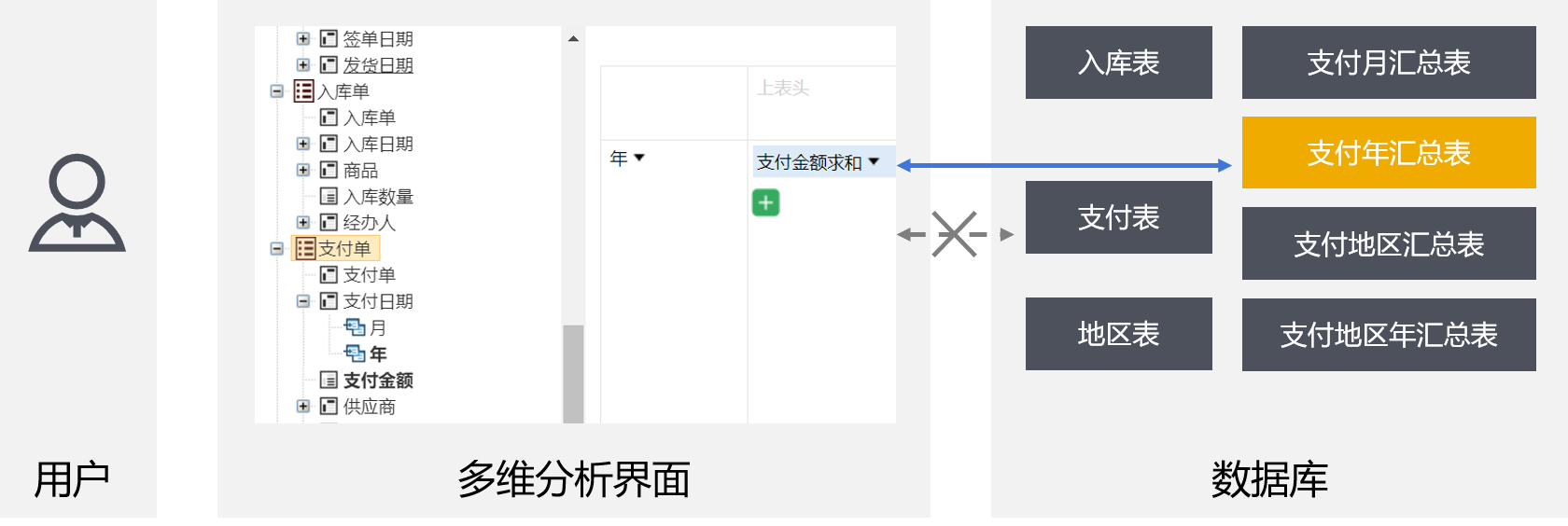
用户基于“支付单”按年汇总金额,会被引擎自动指向“支付单年汇总表”查询,而不会使用更基础的“支付单表”,而在页面上用户只基于“支付单”进行操作
多维分析查询结果以多图表形式组合到dashboard中,并共用全局参数

润乾bi提供跨异构库查询能力,实现面向异构库查询的多维分析

润乾bi可以集成嵌入用户已有应用,同时也提供独立的平台管理系统—润乾报表中心。润乾报表中心开源免费

*基于润乾bi核心功能,加上开源的bi管理系统,助你快速打造属于自己的bi产品

润乾bi采用全面html5输出,适配各类终端(不提供移动app,需集成嵌入使用)吗,




业务人员在web端,填报新的数据,并保存到后端数据库中(或其他数据存储)
补全缺失的数据,或者维护修改老数据,并更新到数据库中(或其他数据存储)

润乾报表是标准的j2ee结构,可以无缝集成到用户的java应用中,方便用户统一管理


在润乾类excel的设计器(ide)中,配置数据源,设计表格,用向导自动生成数据来去脚本

润乾是标准j2ee结构,把润乾的应用包,复制到应用系统中,xml文件配置数据源信息,编辑jsp文件配置展现报表的tag标签

然后在浏览器中输入url,访问对应jsp,就可以进行填报了,填报可以手动填报,也可以导入excel中的数据来填报

常规网格式报表填报

可以增加、插入、删除行,进行数据的增删改

用户根据需求,自由定义数据填报格式

同时向相关的不同表中填报数据

支持多源填报,数据来去无关,初始数据可以来自,不同库,文件或者json等,回填数据同样可以去向任意不同数据源

像excel的多sheet表格一样,可以多个sheet同时填报,来源和去向同样可以多样性

导入现有excel模板,当做填报模板,节省开发工作量

填报表格,可以导出excel,用于本地保存,或者离线填报

导入excel的数据进行填报,也可以整体复制粘贴填报

多种编辑风格,编辑框/复选框/上下载文件/下拉列表/下拉数据集/下拉日历/下拉树。辅助用户快速录入,还能保证格式和数据的正确性

可以根据同一表填写的数据,自动计算出其他的指标数据。订单金额=单价*数量*(1-折扣)

还可以跨表取数,对不同表中输入的数据进行自动计算。包含“几”类产品是根据“订单明细”表中“产品id”数量计算的

各种类型的数据都可以做验证,保证数据的正确性

传统填报工具只会:
“一来一去,哪来哪去”
复杂填报场景需要:
“多来多去,来去无关”
数据来源和回填的表是同一个表,数据从哪里来,回哪里去。

报表的不同区域是不同的数据来源,修改后,还可以回填到不同去向中。

传统工具基本解决不了这么复杂的填报需求
通过脚本可以连接主流的各种关系,非关系型数据库,以及文本,json,http型数据源

通过脚本可以灵活定义数据来源与去向,对数据流动的路径进行更精准、深度的控制,解决各类复杂的多来多去复杂场景

数据来源可能是excel,json,oracle,mongodb,数据去向可能是mysql,hive,redis等,不管多复杂,两个脚本都搞定
由业务发起人根据需求,灵活、自由定义的数据填报采集表格


润乾的填报模型,可以自动识别数据结构,把填写的数据结构化保存,并可以直接针对这些结构化的数据进行后续的分析



上级单位业务人员根据业务需求,实时制作填报模板

填报引擎可以自动识别数据结构,下面这种样式复杂的,都可以识别

下级单位在网页上填报,或者下载excel后离线填报,再上传

上级单位制作汇总模板,填报完成后,自动汇总结果

上级单位针对汇总结果进行bi多维分析(买报表赠送bi),业务填报全流程到此结束
